基于云原生的电话 SDK 日志收集系统
撰写于 2022年1月14日 修改于 2025年5月24日 分类 编程杂记 views
部门内的电话 SaaS 业务提供了一个电话 SDK,可以方便有开发能力的客户在自己的系统和软件中集成电话功能。电话作为一种实时通信业务,有很多不同的状态,且涉及电信运营商和集成商,与网络状况、坐席状态、被叫号码状态都有着密切的关系,如果一通电话出现问题,开发同学想要复现难度很大,因此对日志的记录和上限显得尤为重要。电话 SDK 使用了一个自研的日志系统来实现日志上报,帮助开发同学在自己的浏览器上复现问题,利用问题现场的数据来进行断点调试,提升解决问题的效率。我在其中负责将浏览器中的日志提交到日志系统,对日志做一些处理、转换、存储,再提供接口给日志工具查询。
本文摘录自部门公众号 企点电话SDK的日志追踪系统 一文中我编写的部分,
日志的服务端存储和查询
电话 SDK 中的线索日志以还原用户现场为目标,因此日志中除了记录行为操作数据,还需要记录上下文情况,HTTP / Websocket 的请求和响应等等,相对于数据埋点中的日志,电话SDK日志单条长度更长、日志的内容也更多样。在查询日志时,会利用多种条件进行筛选,还需要支持准实时的检索能力。相对来讲,对日志的保存时间要求并不长,几天到几周即可,也没有复杂的聚合和分析需求,日志入库后,一般不会对其进行二次处理和再分析,根据日志的查询需求和空间占用情况,定期进行清理即可。前端收集到日志并提交到日志收集接口后,后续大概会有如下几个步骤:
- 接口收到日志后,立即返回响应,并将收到的日志推入消息队列
- 从消息队列中消费消息,对日志进行清洗、数据整理等操作
- 将整理后的日志持久化
- 提供日志的实时查询和统计服务,查询需要支持按字段检索和全文检索
日志系统的基本架构
对于常规的日志收集系统,主要可以分为接口层、日志处理层、日志存储层、数据展示层四大部分。
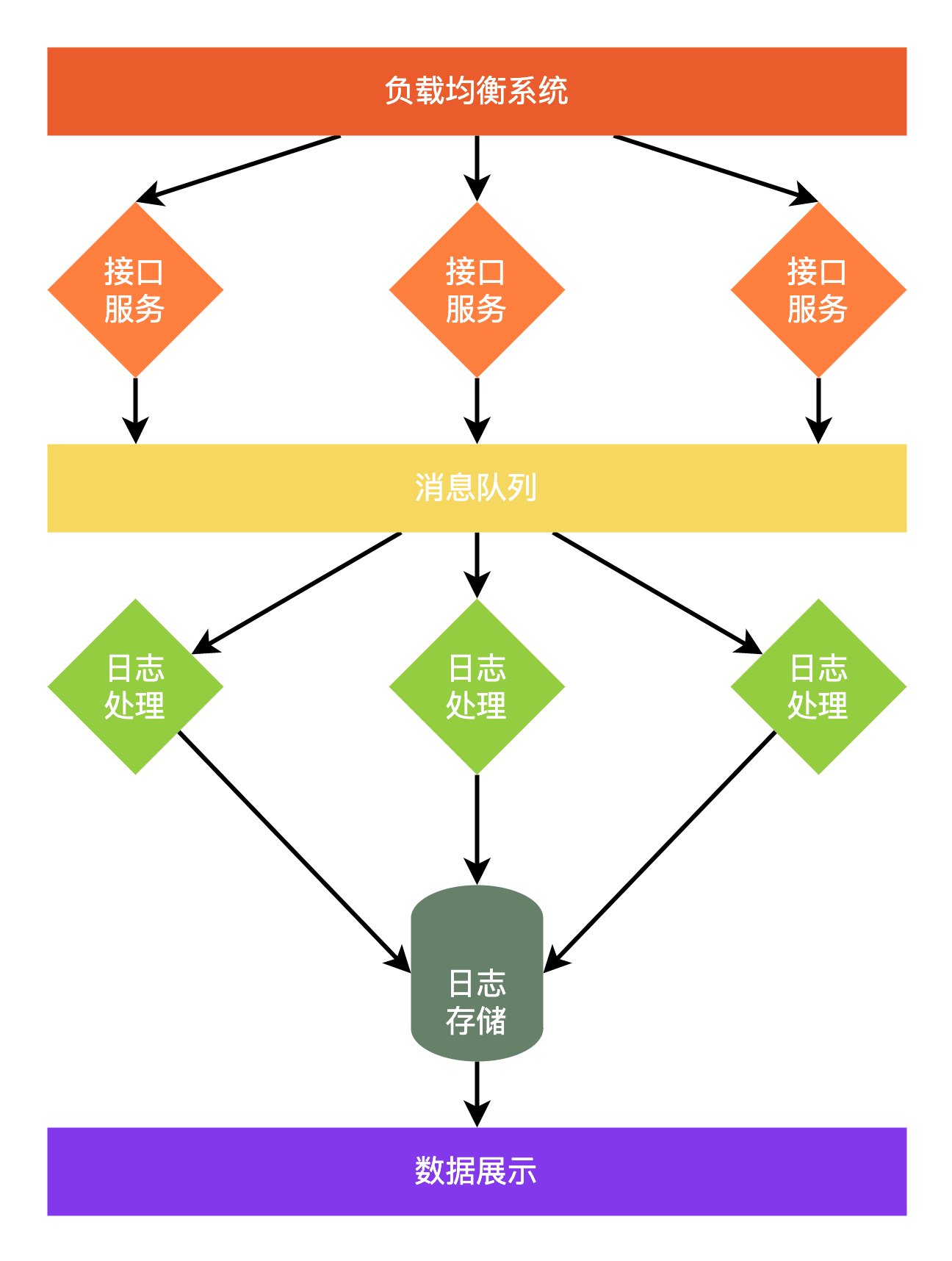
接口层需要考虑日志的高并发、上传量大的特点,在确保接口稳定的前提下,提升接口返回速度,保证日志的完整性。通常情况下,这一层会加入负载均衡系统,根据一定的策略将日志分发给接口层服务,接口层服务一般不处理日志,只将日志转换为统一格式的消息,推入到消息队列。利用消息队列对日志进行缓存和分发,对日志生产进行消峰,只要消息积压不太严重,一般不需要调整接口层服务的数量。
日志处理层中会对日志进行解析,保证日志的结构正确,对于截断或损坏的日志进行单独的记录。由于电话 SDK 会有多个版本,不同版本之间提交的日志会不一样,有的字段的值类型不一样,有的同一字段位于日志 JSON 中的不同位置。都需要在这一步对日志格式化,做一些类型和含义上的转换,补充缺失的字段等。日志处理层通常是从消息队列中订阅和消费消息,进行上述的处理后,将日志存储到日志存储层。
日志存储层提供日志的存储、查询和聚合。一般日志按时间存储,即可便于查询,又能方便管理。例如 Elasticsearch 可以按时间创建索引,查询时可以根据时间来精确查询范围,提升查询的效率,也能方便快捷的删除过期的日志。
数据展示层主要是提供日志的查询接口,有些日志系统还需要 dashboard,提供对日志收集情况、日志本身的统计和分析能力,比如 Kibana 就提供了对 Elasticsearch 中的数据可视化、查询、索引管理、节点状态管理等功能。
日志存储的技术选型
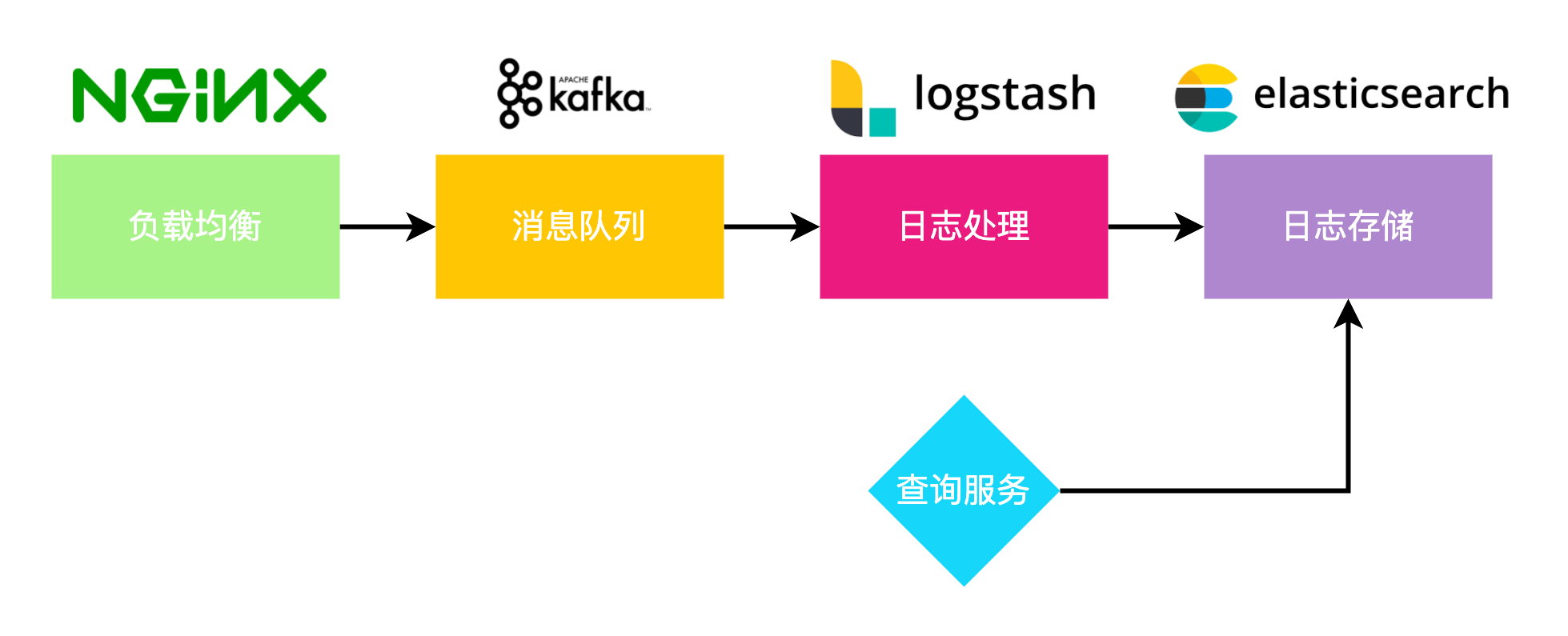
传统的技术选型
根据对日志规模的初步估算,预计每天日志数量在千万级别,空间消耗数十G,对于主流的日志解决方案,基本都能满足需求,以 ELK 方案为例,可以使用 nginx 作为负载均衡,将请求转发到 Kafka 消息队列,用 Logstash 消费消息,处理数据,转存至 Elasticsearch。再构建一个服务,专门从 Elasticsearch 中查询日志。
基于云原生的技术选型
虽然 ELK + Kafka 的方案可以满足我们的需求,但是这个方案还是需要搭建多个服务,并且可能还涉及到服务的扩容问题。经调研发现,腾讯云提供的云原生生态,也可以实现上述构架的相关功能。
云原生(Cloud+Native)是一套基于云来构建和运行服务的方法、体系、工具和服务,从设计之初就考虑利用云上的各种资源和服务,实现弹性伸缩的分布式架构,云原生代表性的技术包括微服务、容器化、DevOps等。
云原生架构非常适合日志系统。弹性伸缩可以轻松应对日志收集时的波峰问题,消息队列、日志处理、数据存储之间也是典型的分布式架构,利用云上的服务,通过简单的配置即可实现负载均衡、消息队列、数据存储这几大部分,只需要将精力集中在编写日志清洗和处理的代码,后期几乎没有运维成本,利用云原生的监控功能,可以方便的了解系统的整体运行状态。
Serverless Computing 无服务器计算是在 PaaS 的基础之上构建的一种代码执行平台,也叫Function as a Service,函数即服务。对于平台的使用方而言,不需要关注服务器的细节,只需要编写代码块,处理函数的输入和输出,即可直接使用云平台的计算资源。阿里云提供的函数计算,腾讯云和华为云提供的云函数,都是 Serverless 概念的实现。比如腾讯云的云函数服务,提供了一整套的开发工具,在开发环境中就可以直接编写和提交代码到云函数中,支持使用 Node、Python、Go、PHP、Java 编写代码。云函数根据函数的运行时间计费,通过设置最大并发数量,可以提升波峰的处理能力。
云函数本身并不能直接对外提供 http 服务,需要绑定到 API 网关才可以。API 网关可以实现对接口测试、预发布、发布的全生命周期管理,还提供了文档生成、测试、访问日志和监控、流量与权限控制等功能。API 网关本身部署在分布式集群上,可以承载较大的访问量,结合云函数,可以实现弹性伸缩。
借助云上已有的消息队列、Elasticsearch 服务,使用云函数处理请求、转换日志、存储日志,利用 API 网关对外提供日志提交接口,定时触发云函数来管理 Elasticsearch 的索引。
为了保证单个云函数的可维护性,一个云函数一般只完成一个功能,我们需要创建如下几个云函数:
接口云函数
触发方式为 API 网关,处理外部提交的日志,解析出请求中的日志数据,检查日志格式,将日志组合为 Kafka 的消息,并推送到消息队列。API 网关会根据当前接口的请求情况,动态增加云函数的实例数量,直到达到配额上限。
日志处理与转存云函数
触发方式为 Kafka ,当有新消息时会调用云函数,检查消息中的日志数据,根据具体规则进行格式化和转换处理,通过 Elasticsearch 的 API 接口来保存数据,为了提高效率,可以接收多个 Kafka 消息后,再合并多条日志,通过 Elasticsearch 的 Bulk 操作批量存储日志。本云函数在系统中较为重要,当出现日志格式问题、转换发生异常,或者存储出现错误时,可以触发警告。
日志查询云函数
触发方式为 API 网关,供 logViewer 插件日志展示时使用。处理日志的查询,主要是构造 Elasticsearch 的 DML 查询语句,再将结果作为接口响应返回。
Elasticsearch 索引管理云函数
定时触发,通过 Elasticsearch 的接口,查询当前的磁盘占用情况,超过一定比例时,根据索引名字中的时间,删除最早的索引,释放磁盘空间。
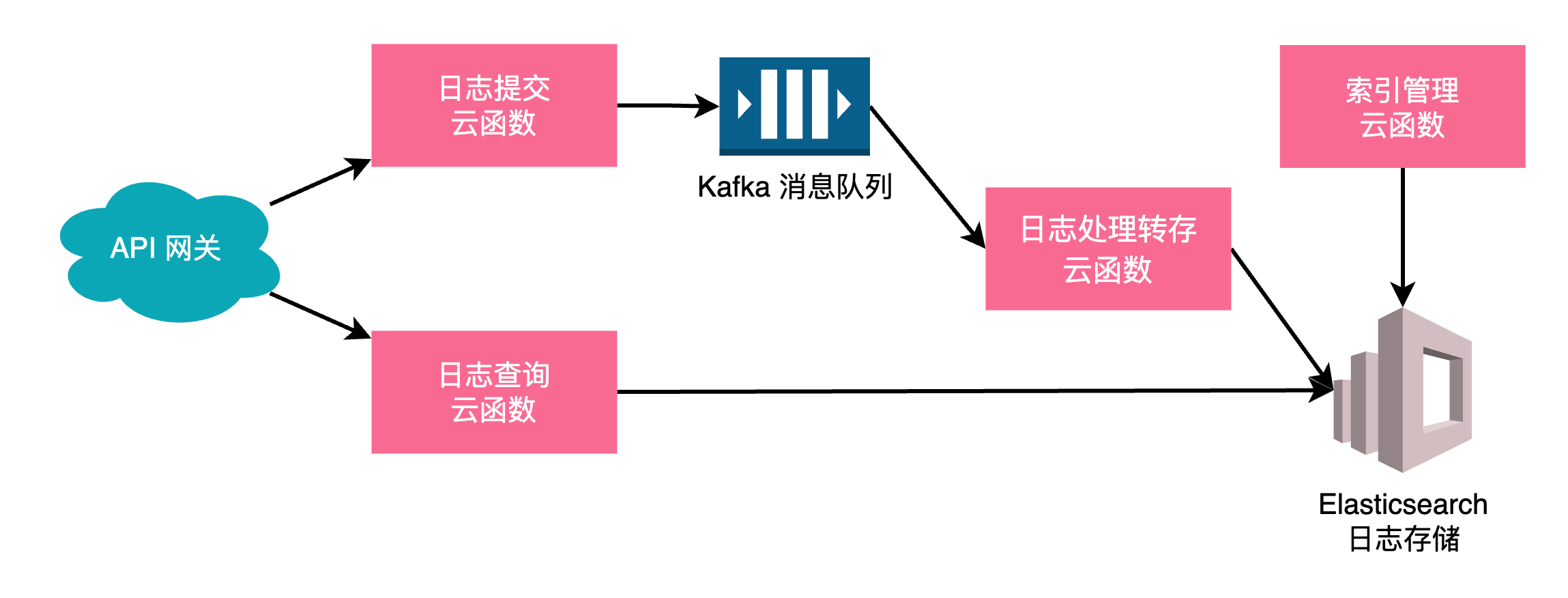
基于云原生的日志收集架构,无需传统的负载均衡,可以自动根据并发数量弹性伸缩计算资源,各服务基本也是按使用情况计费,无需专门的维护人员,通过云平台提供的监控工具,可以直接查看系统的处理情况,能够低成本的满足我们的日志收集需求。